
tl;dr: remote HTTP APIs enabled the development of native web apps, but they’re not really suited to the real world of mobile users. A sync-capable client-side database enables you to build offline-first applications.
PouchDB is a JavaScript-based database that runs on the server and on the browser and that is able to sync when the network is available.
I built a bunch of modules to make building this easier.
Proof-of-concept demo: code and screencast.
HTTP APIs are great
Most of developers are used to developing applications that make extensive use of the internet. Typically, these applications initiate HTTP requests to a service to either get or change some state. This service acts as a more or less intelligent data store, supplying or modifying the data as requested. Although the original intent of the web was to simply allow the browsers to get some documents and post some forms, the rise of JSON-based RESTful APIs over HTTP, together with the capability of web browsers to make these, has allowed the rise of ever more complex web applications to be built and has taken us far already.
HTTP APIs are terrible
Yet, this is way of building applications does not map well to reality: the real world, specially on mobile, is made of low quality networks: slow, intermittent and often non-available. What happens when, operating one of these apps, the user of the mobile phone finds itself without a network? If the application error handling is well built, an app-initiated HTTP request will fail with an error message, rendering the application unusable for some time.
We can’t keep building apps with the desktop mindset of permanent, fast connectivity, where a temporary disconnection or slow service is regarded as a problem and communicated as an error.
— Hoodie, Say Hello to Offline First
Worse yet, what if a certain request reached the server, but due to a bad connection, the reply didn’t get to the client in time? The application now doesn’t know the state of the server, and any assumption it makes is bound to be incorrect, potentially giving rise to all sorts of weird behaviors.
From the other end
Given the continuous rise of the share of mobile users, this is an extremely important problem, but it’s not the only problem behind this way of building apps:
By initial design, all HTTP requests are initiated by the client. When the client gets the reply document to a successful request against a remote API, you get a value that is potentially outdated the moment it leaves the server. To get the latest version of this document, the user has to explicitly refresh the page, or the application must keeping asking about state changes to the remote service.
Another alternative is for the server to notify of changes when they happen — hence the appearance of AJAX long-polling, server-sent events and lately, WebSockets. These hacks, techniques or technologies allow the server to asynchronously notify the client of any relevant state changes. But this poses a reliability problem: in the face of intermittent networks, the server has to buffer the changes for a long (infinite?) time or risk the client loosing them.
Sync to the rescue
Sync protocols may come in handy in solving these types of problems. Generally, a sync protocol is a way for two or more parties to be aware of the state of each other over an asynchronous communication channel. You send me your changes, I send you mine, we resolve any conflicts and we’ll both eventually agree on the same state. And we repeat.
Sync is used every day in popular Cloud-based services like iTunes, iCould, Dropbox, Google Drive, Evernote and many many others as a way to keep data in sync across devices.
Unfortunately, sync protocols are hard to implement (you can find this out by simply googling “sync errors”). Either because it’s being bolted on as an afterthought, or simply because it has many edge cases, sync often leads to a frustrating end user experience: documents, photos or audio tracks that don’t replicate, duplicate records, lost data, and all sorts of misbehavior that we experience often as consumers of distributed apps.
Say hello to CouchDB
CouchDB is an open-source database that was built from the ground up to be sync’able. It allows to have one database replicated across several nodes. When a document in a database is created, removed or changed, that change will eventually reach the other nodes if they keep trying syncing with each other. Also, if there are conflicting updates on a given document, the protocol guarantees that all the nodes will eventually agree on the same version.
…and PouchDB
CouchDB is built on Erlang and designed to run on a server, but it has a close JavaScript cousin named PouchDB. PouchDB runs on Node.js, on the web browser and its HTTP adapter is compatible with CouchDB. At least for some types of apps, having a database like this on the client allows the app to perform the changes locally and then simply rely on sync to propagate them into a central place. And since syncing can be two-way, we can also get changes from the server propagated into the clients.
And if we have several clients syncing to and from the same central database, they can collaborate with each other, and, network conditions permitting, do it in real-time.
The state of the art
Out of the box, PouchDB can communicate with a central PouchDB or CouchDB server, keeping them in sync, by using a technique called HTTP long-polling. When using this technique for syncing two databases, the client keeps a dangling HTTP request unanswered until the server has a change to inform you. Once a change happens the server replies that, terminating the request. Then the browser initiates an long-poll request again, etc.
If you use the socket-pouch client adapter and server written by Nolan Lawson, you can do the same but in a continuous fashion using WebSockets (or some fallback mechanisms for older browsers — it uses Engine.io under the hood).
Demo time!
Recently I started putting together a proof-of-concept for a customer using some of these technologies. This demo-to-be had these minimum requirements:
- Use a React-based web interface,
- Allow having several humans (on mobile an desktop devices) collaborating on editing a set of documents
For the public version of this demonstration, I chose to show you a Todo application (based on the TodoMVC boilerplate). Here is the code and the demo video (Youtube).
Architecture
Roughly, these are the boxes of the high level components that matter the most for this system:
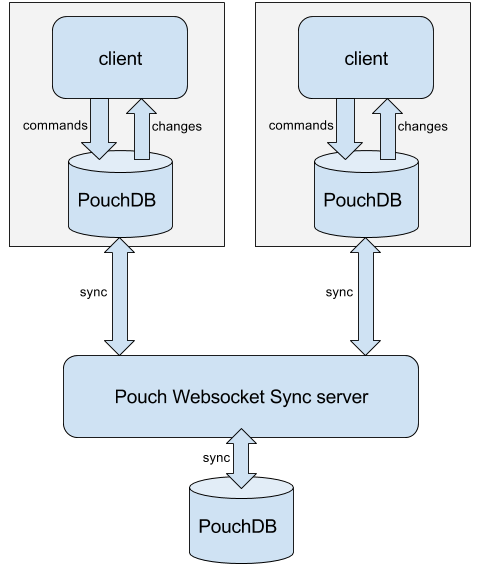
Each client keeps its own local database that’s kept in sync with the UI by:
- translating changes happening in the UI store into PouchDB commands and
- propagating database changes into the UI.
The local PouchDB database is then kept in sync with a central PouchDB server using a WebSocket client that talks to a WebSocket server.
When two clients are working against a replica of the same database, their state is kept in sync with each other. This happens indirectly through the syncing happening between the remote and any of the local databases.
Now, the open-source
Resting on the shoulders of all the great aforementioned and other open-source work, I rolled up my sleeves, entered the rabbit hole and a few months later came out on the other side holding a bunch of new packages I’d now like to share with you:
pouch-websocket-sync-example
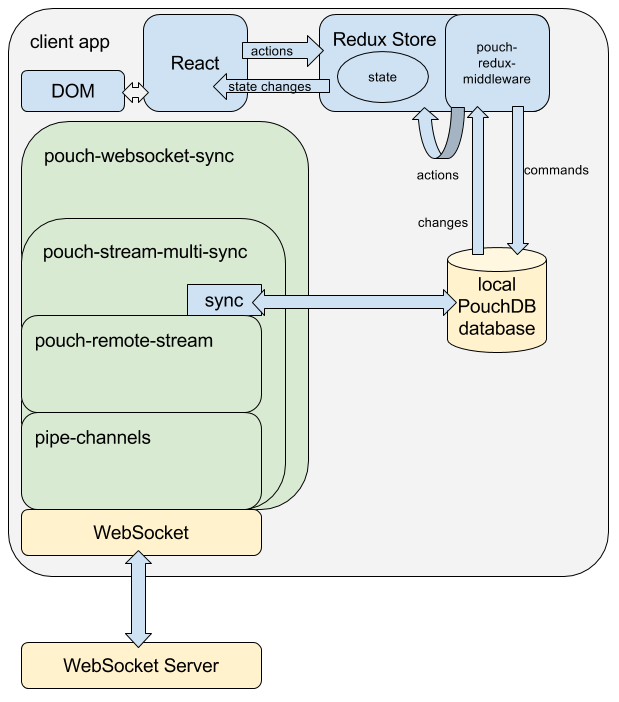
All the code required to create this demo, based on the Todo MVC boilerplate. Underneath it uses React, Redux, pouch-redux-middleware and pouch-websocket-sync (both explained later). The most interesting part (and the only one that deviates from a standard React / Redux boilerplate) is the setup of the Redux store.
Please feel free to use this to bootstrap your offline-first sync-based collaborative native web app!
pouch-redux-middleware
Redux is an agnostic and predictable state container that you can easily plug into React. It has now become more popular than Flux, the original state-management approach Facebook created.
This module is a Redux middleware that allows you to sync any changes happening on your store into a PouchDB database and the reverse. It allows you to write synchronous actions and standard reducers: besides making it dead simple to bolt on a local persistence of your Redux state store, you can simply retrofit this middleware into any existing Redux implementation.
Also, unlike other existing implementations at this time, this one allows you to individually sync each document separately, instead of saving the whole state as one document.
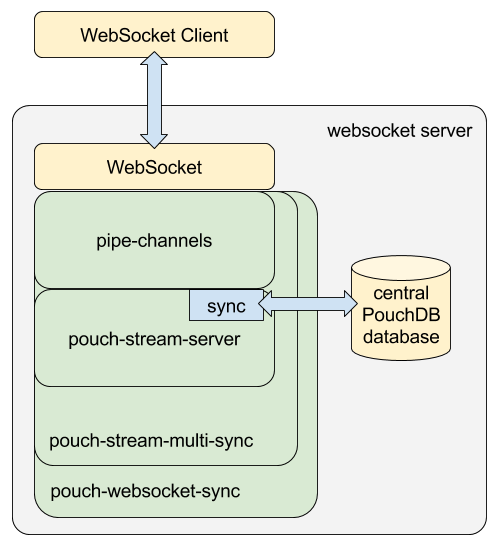
pouch-stream-server
This module allows you to generate generic PouchDB streams against any given PouchDB database. It exports a generic streaming interface that can be piped into any other stream (a server-side websocket, a TCP server connection or any other — yay streams!).
pouch-remote-stream
This other module provides you with a stream-based client adapter that you can pipe to and from any duplex stream, it being a web socket, a TCP client connection or any other. Again, yay streams!
pipe-channels
Using the great mux-demux module as back-end, it allows you to multiplex negotiation channels and data channels inside one stream. This is what gives us:
- the capability of using the same stream to handle many databases and also
- the chance of deciding whether to allow the access to certain databases based on user credentials during negotiation.
pouch-stream-multi-sync
This one allows you to sync several PouchDB databases through a single stream. It has a stream-providing server side interface that allows you to approve or deny database access requests and also a stream-providing sync client that reconnects when needed. It exports streams so that again, you can use them in any streaming context.
pouch-websocket-sync
Very thin layer over the previous module that exposes the streams as a web socket server and client.
That’s an awful lot of modules!
Yes it is, but you only need this last one of these to make it all work — check out the store setup for the Todo App.
Putting it all together
Here is a diagram of how these modules are being assembled together in this solution, on the client side:
And here is the server side:
In this type of setup, the client can make any change in the database and that gets replicated into the server. Isn’t this open to being exploited?
Well, yes and no. The authentication and authorization is left at the hands of the server implementation. On the server side you have the possibility of denying the access to any given database given aribitrary data passed in by the client at the time of the negotiation. This data may contain some credentials: a secret or any kind of authentication token that allows the server to verify the identity of the user.
But yes, the server has no control over what data is being written. This is why this type of architecture only serves for personal / shared databases, not for public records.
If you need to change central records and still want to use these offline-first capabilities, there are some interesting patterns that you can build on top of this. It may envolve using server-side change listeners that treat each document change as a request to change the central data, acting as clerks on behalf of a central system. — but this would be the subject a future article…
More databases
This example only uses one database, but all these modules allow you to sync many databases into a client using only one stream (one websocket in this case).
What now?
Nothing more for now. I suggest you try / tweak this demo or fiddle with any of these modules, and, as always, feedback is truly appreciated.
Enjoy!




